Legal Document Secrets: Data Extraction Demystified
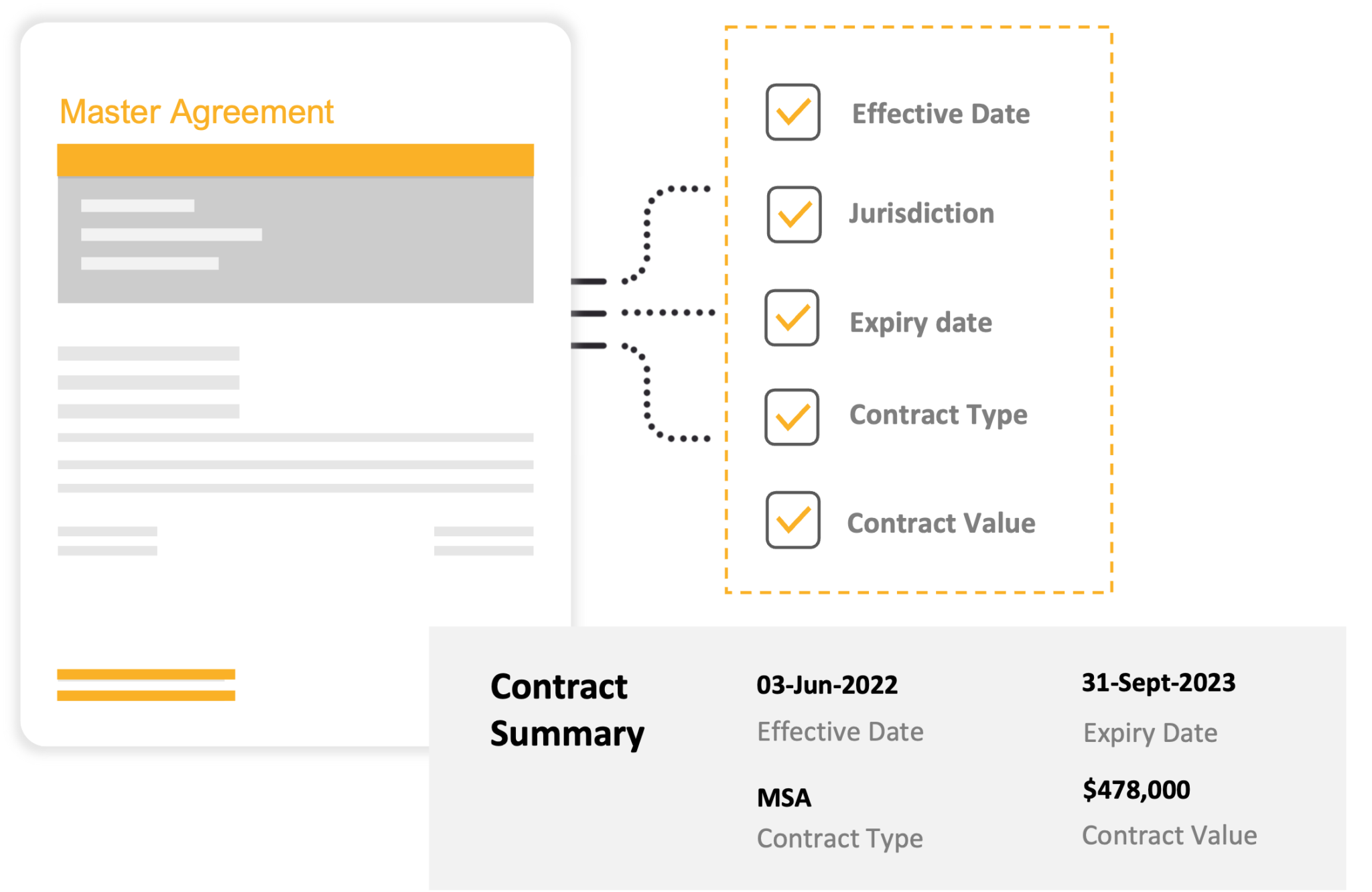
- What is a Legal Document?
- What Data is Found in a Legal Document?
- Importance of Extracting Data from Legal Documents
- How to Extract Data from Legal Documents Manually?
- Step 1: Review the Legal Document
- Step 2: Use Highlighting and Annotation
- Step 3: Manual Data Entry
- Step 4: Verification
- Step 5: Organize and Categorize
- Step 6: Data Standardization
- Step 7: Data Security and Confidentiality
- How to Automate Data Extraction for Legal Documents?
- Step 1: Upload Your Document
- Step 2: Configure Data Fields
- Step 3: Start Extraction
- Step 4: Review & Validate
- Step 5: Download
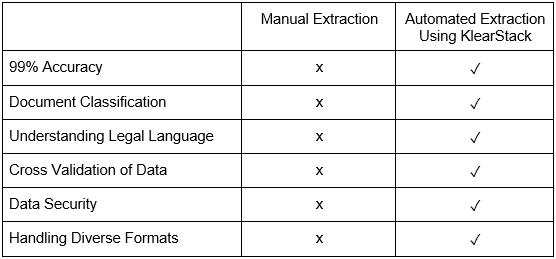
- Manual Vs Automated Data Extraction from Legal Documents
- Why KlearStack is the Best Choice for Extracting Data from Legal Documents?
- Conclusion
- FAQs
- 1. What is keyword extraction for legal documents?
- 2. What is document data extraction?
- 3. How do you extract data from unstructured documents?
- 4. How do legal professionals use OCR?
In the world of legal document management, efficiency is the key to success.
This blog is your guide to extracting data from legal documents with accuracy.
Discover practical steps, expert tips, and best practices to streamline your workflow and boost productivity.
What is a Legal Document?
A legal document is a written record that holds legal significance and is used to establish rights, obligations, or agreements between parties. These documents can take various forms, such as contracts, court filings, deeds, wills, and more.
What Data is Found in a Legal Document?
Legal documents contain a wide range of data, including:
- Textual information,
- Dates,
- Names of parties involved,
- Legal terminology,
- Case numbers, and specifics related to legal matters.
This data is crucial for legal proceedings, compliance, and decision-making.
Importance of Extracting Data from Legal Documents
Extracting data from legal documents is essential for several reasons.
- Organizing and analyzing legal information becomes easier.
- Saves time, minimizes human errors, and enhances efficiency in tasks related to legal document management.
- Maintainsdata security, confidentiality, and compliance with the judicial process.
How to Extract Data from Legal Documents Manually?
While manual data extraction can be done without specialized tools or software, it often involves repetitive activities and carries the risk of human errors.
Here's a step-by-step guide on how to manually extract data from legal documents:
Step 1: Review the Legal Document
Start by thoroughly reading the legal document to understand its contents and structure. Identify the specific data points you need to extract, such as names, dates, contract terms, or case details.
Step 2: Use Highlighting and Annotation
Use colored markers or digital tools to highlight and annotate the relevant information within the document. This can help you quickly locate and reference key data points.
Step 3: Manual Data Entry
Extract the identified data manually by typing it into a digital document or spreadsheet. Ensure accuracy and consistency while entering the information.
Step 4: Verification
Double-check the extracted data for errors or omissions. Cross-reference it with the original document to ensure precision and completeness.
Step 5: Organize and Categorize
Create a structured format for organizing the extracted data. This may involve categorizing data into sections, creating tables, or using specific data formats as needed.
Step 6: Data Standardization
Ensure that the extracted data follows standardized formats and conventions, especially if you're dealing with multiple legal documents or want to maintain consistency.
Step 7: Data Security and Confidentiality
Pay special attention to data security and confidentiality when manually handling sensitive legal information.
Store and transmit data securely to prevent unauthorized access.
How to Automate Data Extraction for Legal Documents?
Here's a step-by-step guide on how to automate data extraction for legal documents using automated data processing solutions like KlearStack:
Step 1: Upload Your Document
Begin by logging into your KlearStack account and click on the Upload Document button.
Upload your legal documents, whether they are scanned copies or received via email, effortlessly.
Step 2: Configure Data Fields
Within the KlearStack interface, set up data fields you wish to extract (e.g., names, dates, case numbers).
Step 3: Start Extraction
Select your prepared documents and activate KlearStack's automated extraction process. Let it do the work for you.
Step 4: Review & Validate
After extraction, meticulously review the data for accuracy and completeness using KlearStack's built-in validation tools.
Step 5: Download
Download the extracted data in the following formats, depending upon your needs:
- CSV
- Excel
Manual Vs Automated Data Extraction from Legal Documents
While manual extraction is a viable option, it may not be the most efficient or accurate method, especially when dealing with a substantial number of legal documents.
On the other hand, advanced automated data processing solutions, like KlearStack offer significant advantages in terms of efficiency, accuracy, and time savings.
Why KlearStack is the Best Choice for Extracting Data from Legal Documents?
KlearStack stands out as the optimal choice for extracting data from legal documents for several compelling reasons such as automatic document classification, day zero accuracy, straight through processing, cross validation of data, and data security.
- Automatic Document Classification: Classify legal documents accurately, aiding retrieval and precise data extraction.
- Day Zero Accuracy: Achieve 99% accuracy from day one, no templates or manual work needed, saving time and costs.
- Straight Through Processing: Automate your end-to-end legal document processes, enhancing efficiency and compliance.
- Cross Validation of Data: Ensure data accuracy and boost confidence for streamlined workflows through KlearStack’s cross validation.
- Data Security: Robust security measures, including encryption and access controls, protect sensitive legal documents, ensuring compliance and privacy.
Conclusion
If your work involves handling contracts and legal notices, there's no better choice than KlearStack's AI-powered Legal OCR platform.
It empowers you to effortlessly extract crucial information from legal documents in a matter of minutes, streamlining your processes and ensuring precision.
Make the smart switch to KlearStack and elevate your legal document management to a new level of efficiency.
FAQs
1. What is keyword extraction for legal documents?
Keyword extraction for legal documents is the process of identifying and extracting specific terms or phrases from legal texts.
These keywords help in categorizing, indexing, and searching legal documents effectively.
2. What is document data extraction?
Document data extraction involves capturing structured data from unstructured documents, such as legal contracts or invoices. This process converts textual information into a usable, structured format for analysis or integration into databases and systems.
3. How do you extract data from unstructured documents?
To extract data from unstructured documents, advanced techniques like OCR (Optical Character Recognition) and Natural Language Processing (NLP) are used. OCR converts scanned text into machine-readable content, while NLP helps identify and extract meaningful data based on context and patterns.
4. How do legal professionals use OCR?
Legal professionals use OCR to digitize paper documents, making them searchable and editable. OCR enables automated data extraction from legal documents, saving time on manual data entry. It also aids in text analysis, e-discovery, and legal research.